Tool
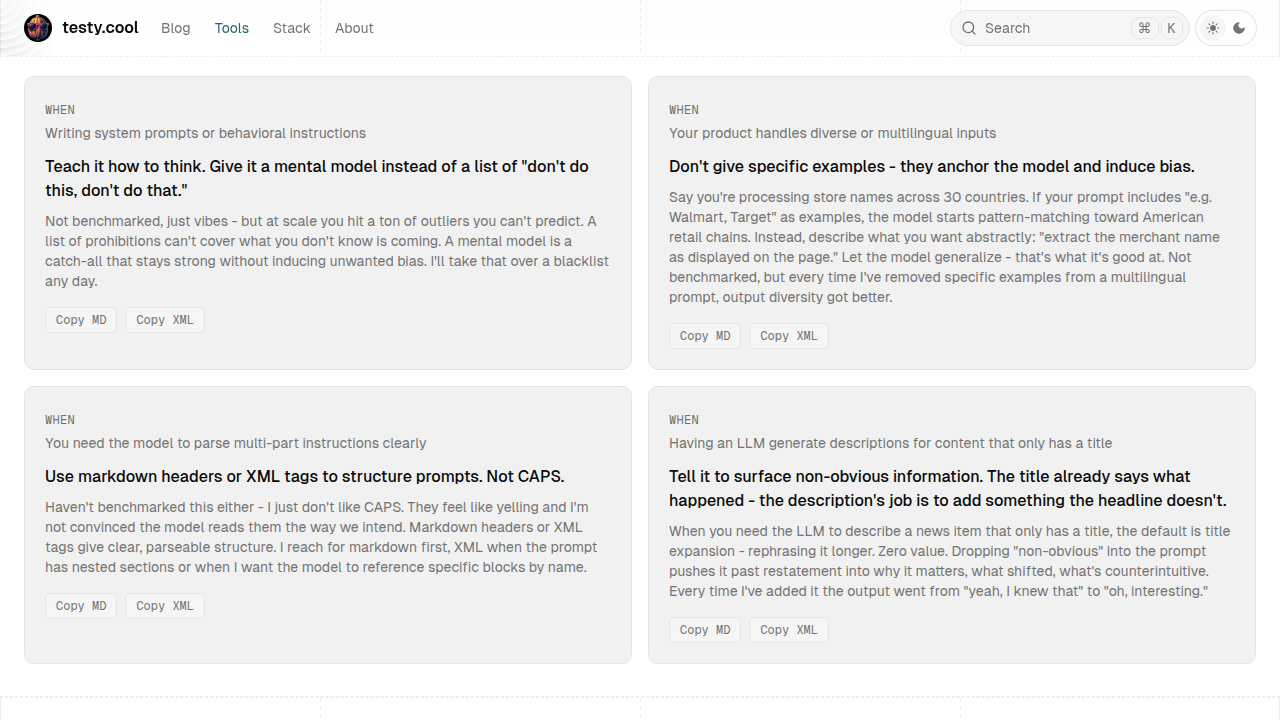
Prompt Field Notes
Context-specific prompting observations. What worked, when it applies, and why. Copy as markdown or XML.
LLMPrompting
OpenDirectory
Tools, a few tool-backed tutorials, and some browser extensions.
Index
Standalone tools live next to tutorial-backed tools, so the useful thing is always one click away.
Context-specific prompting observations. What worked, when it applies, and why. Copy as markdown or XML.
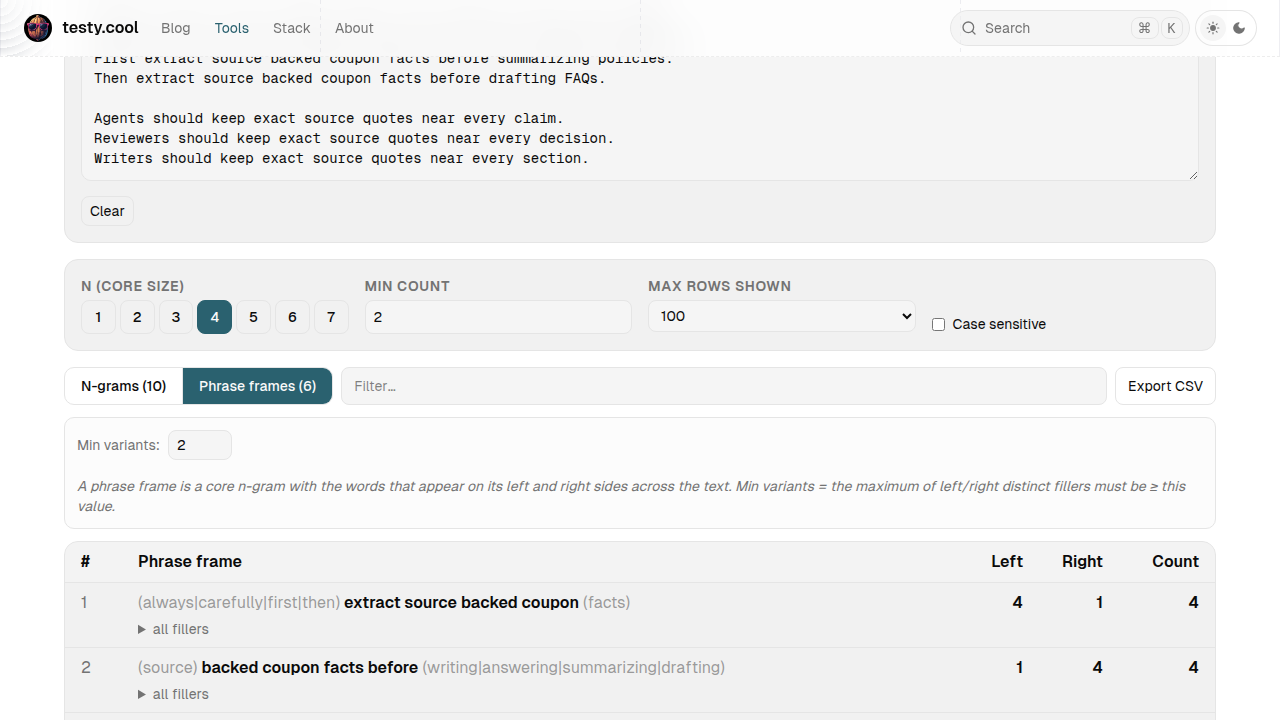
Paste text, get n-gram frequencies plus phrase frames — n-grams with one variable slot so variants collapse into one entry.
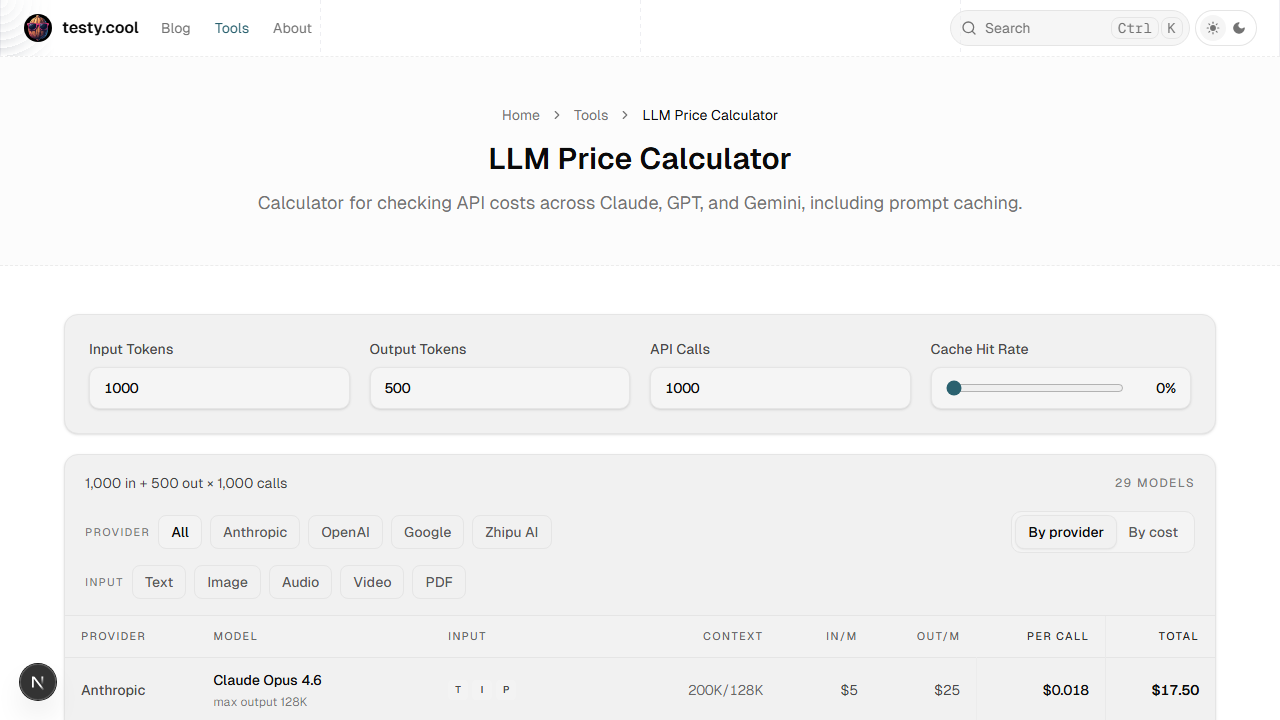
Calculator for checking API costs across Claude, GPT, and Gemini, including prompt caching.
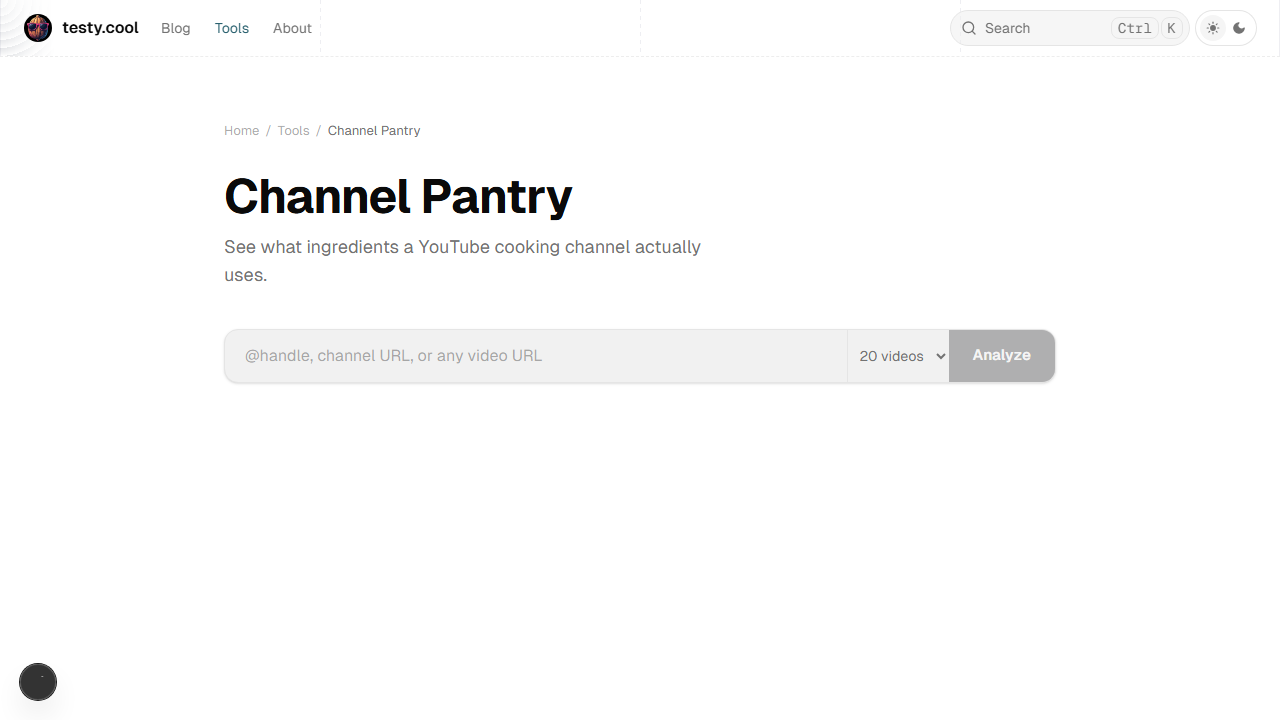
Analyze a YouTube cooking channel to see what ingredients they use most.
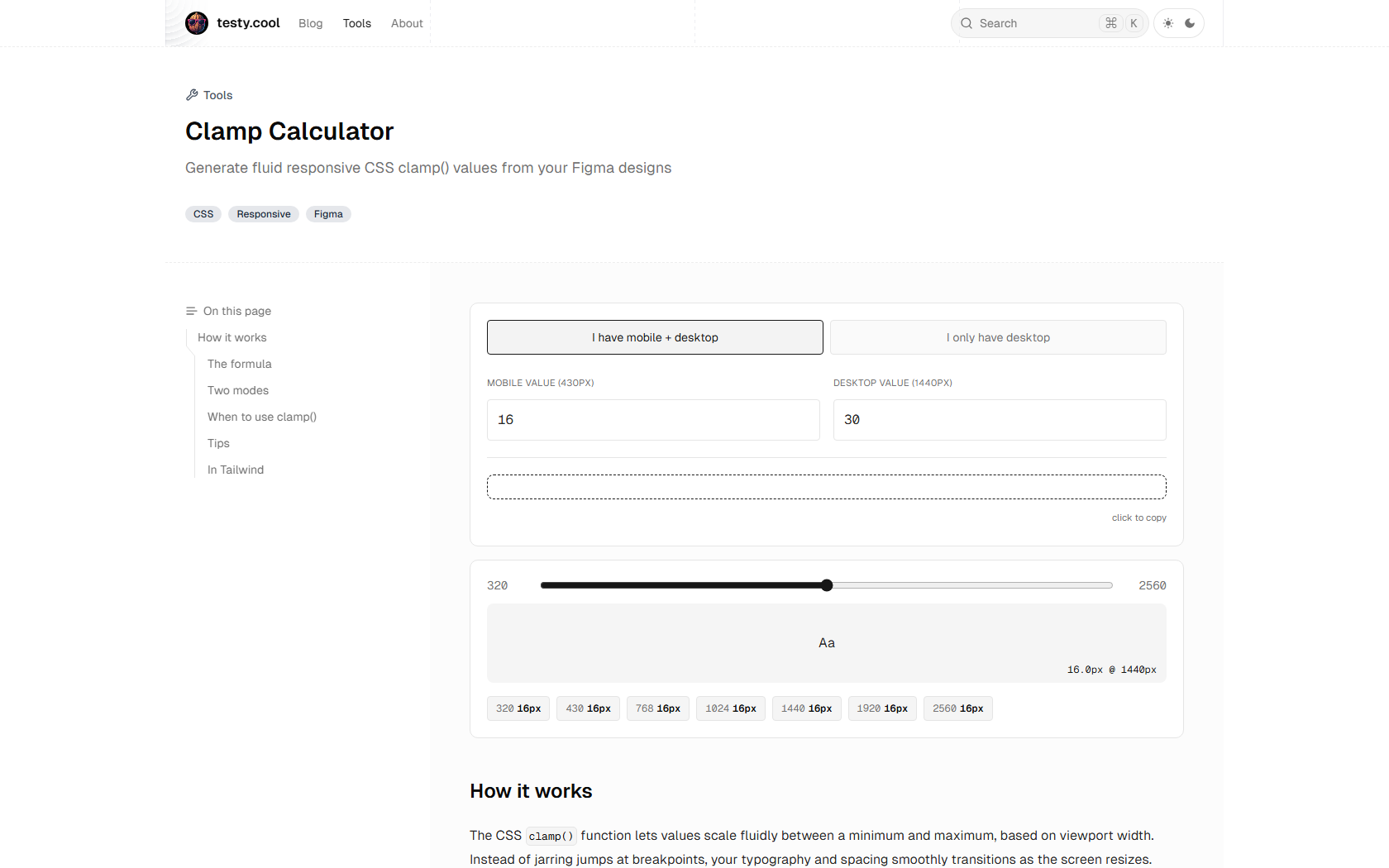
Clamp() calculator plus the tutorial explaining the math behind it.
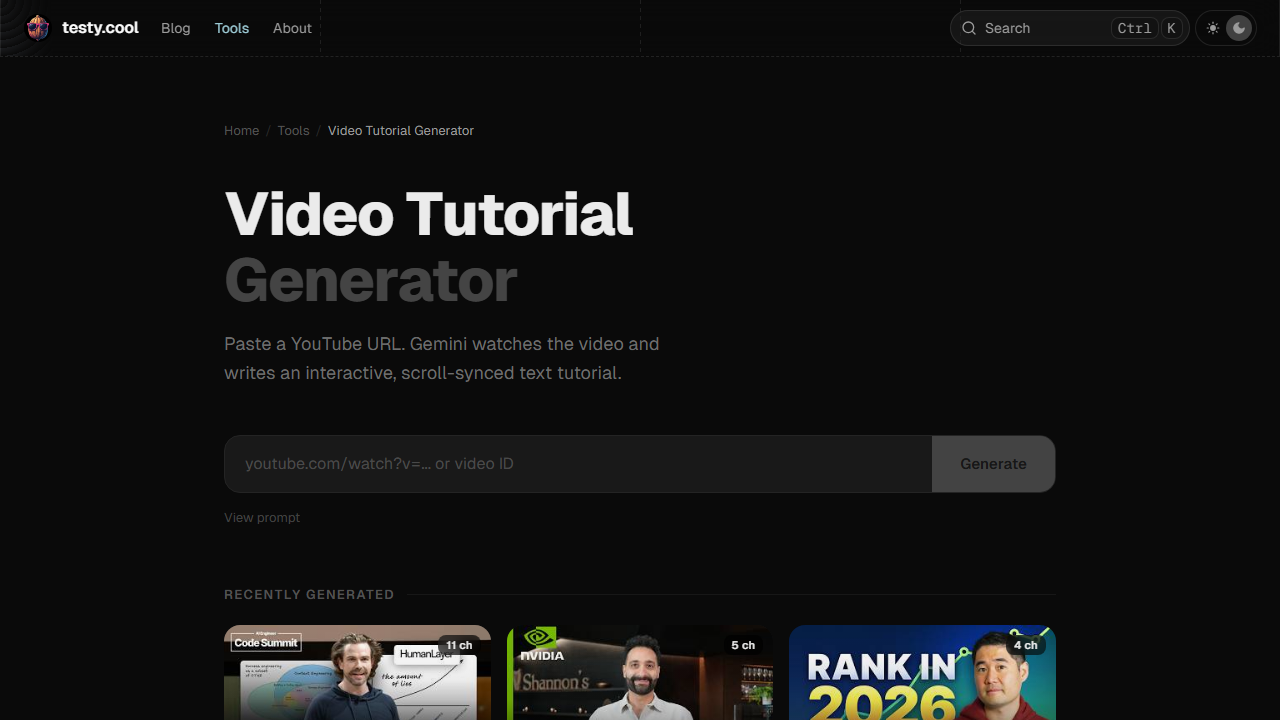
Paste a YouTube URL. AI watches the video and writes a scroll-synced text breakdown.
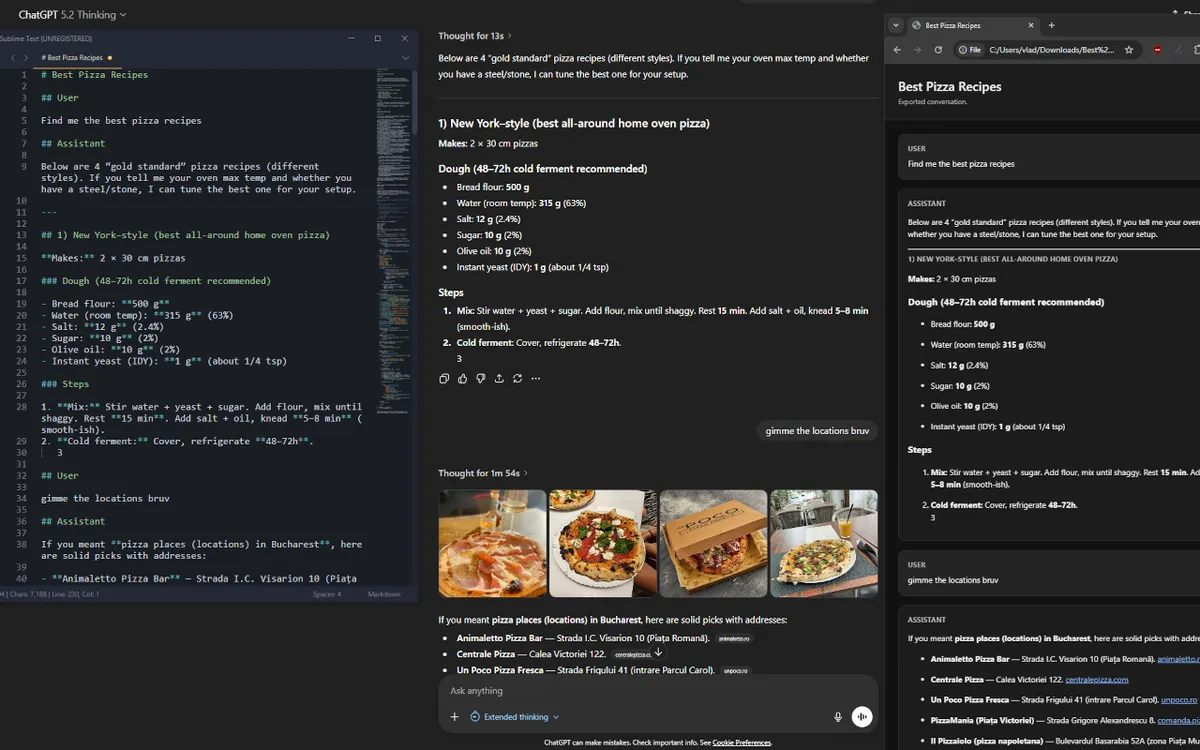
Browser extension for exporting one ChatGPT conversation to Markdown or HTML.
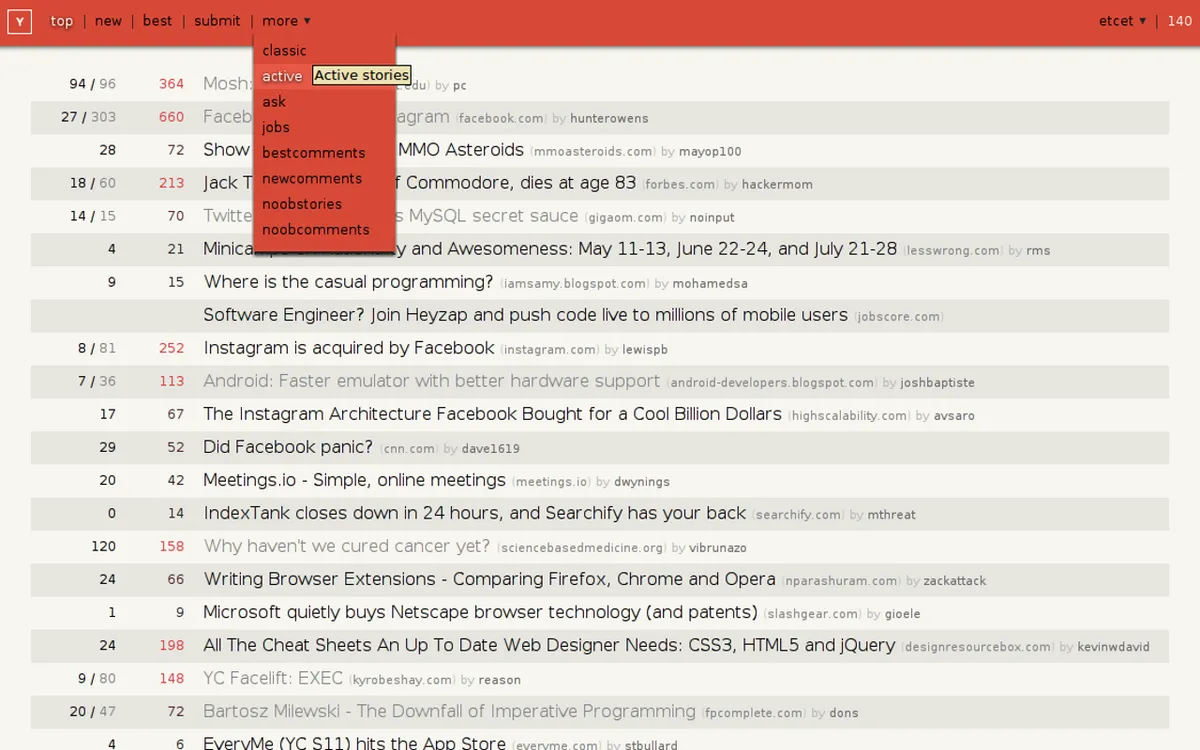
Manifest V3 fork of HNES with collapsible comments, keyboard shortcuts, and user tags.